1. Tujuan[back]
1. Memprediksi apakah seseorang terkena penyakit diabetes berdasarkan beberapa parameter lain pendukung
2. Alat dan Bahan[back] Alat yang digunakan pada pembelajaran ini adalah python pada percobaan ini kita menggunakan vscode sebagai platform open sourcenya
python dibuat pertama kali oleh Guido van Rossum di tahun 1991. Saat ini ada 2 versi, yaitu python 2 dan python 3. Versi yang terbaru adalah versi yang ketiga.
Python dapat digunakan sebagai berikut :
Pengembangan aplikasi web dan seluler back end (atau sisi server)
Pengembangan aplikasi atau perangkat lunak untuk dekstop
Memproses data besar dan melakukan perhitungan matematis
Menulis skrip sistem (membuat instruksi yang memberitahu sistem komputer untuk “melakukan” sesuatu)
Algoritma K-Nearest Neighbors
Kita akan mencari kelas pada titik bintang biru. Bintang biru tersebut dapat dikategorikan sebagai kelas RC atau GS. K pada algoritma KNN merupakan nilai yang kita tentukan. Misalkan K = 3. Sekarang kita akan membuat lingkaran dengan BS sebagai titik tengah yang berdekataan dengan 3 titik poin.
3 poin terdekat dari BS adalah RC. Oleh karena itu dengan confidence level yang baik kita dapat menyatakan BS masuk pada kelas RC. Disini pemilihan sangat menentukan dari totok terdekat dari tetangga dari RC. Pemilihan hyperparameter K akan menjadi sangat krusial
Menentukan Nilai K
Kita akan memahami bagaimana nilai K akan mempengaruhi algoritma ini. Pada contoh terdapat 6 observasi training yang konstan dengan nilai K yang memberikan pembatas setiap kelas. Pemabatasini akan membedakan RC dari GS. Kita akan coba melihat perbedaan dari nilai K terhadap kelas
Jika kita perhatikan maka pembatas akan menjadi lebih halus dengan peningkatan nilai K. Jika K ditingkatkan hingga tak hingga maka semuanya akan menjadi biru ata merah bergantung pada jumlah total.
Error training dan validasi error rate merupakan parameter yang perlu diberikan dengan berbagai nilai K yang berbeda. Berikut merupakan kurva training error rate dengan berbagai nilai K
Berdasarakan grafik tersebut dapat kita lihat. Error rate ketika K = 1 akan selalu nol pada sampel training. Ini karena poin terdekat dengan datapoint adalah dirinya sendiri. Oleh karena itu prediksi ketika K = 1 akan selalu akurat. Jika kurva validasi error sama maka pilihan K yang terbaik adalah 1. Berikut kurva validasi error dengan perbedaan nilai K.
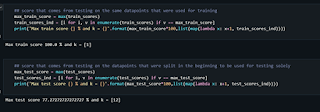
Sehingga ketika K = 1 kita mendapatkan overvitting pada pembatas. Sehingga errorrate akan menurun dan mencapai minima. Setelah minima error rate akan meningkat sesuai dengan nilai K. Untuk mendapat nilai K yang optimal maka kita akan memisahkan training dana validasi dari dataset.
Perlu juga dicatat bahwa ketiga ukuran jarak hanya berlaku untuk variabel kontinu. Dalam contoh variabel kategori, jarak Hamming harus digunakan. Ini juga memunculkan masalah standarisasi variabelnumerik antara 0 dan 1 ketika ada campuran variabel numerik dan kategoris dalam dataset.

























Tidak ada komentar:
Posting Komentar